存储结构
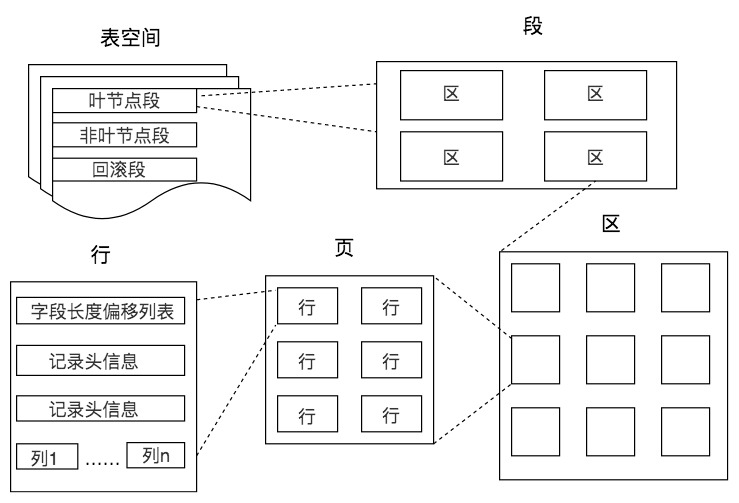
页(Page)
页是数据库管理存储空间的基本单位,一个页中可以存储多个行记录,记录在页中按照主键值从小到大以单向链表的形式存储的。
区(Extent)
区是比页大一级的存储结构,是一个连续分配的空间。在 InnoDB 存储引擎中,一个区拥有 64 个连续的页,一个页的默认大小是 16kb,所以一个区的大小是 64*16KB=1MB。
段(Segment)
段由一个或者多个区组成。段中的区与区之间不是相邻的,所以段可以不是连续的空间。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。
表空间(Tablespace)
表空间是一个逻辑容器,表空间中存储的对象是段。一个表空间可以含有很多的段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
在 InnoDB 中有共享表空间和独立表空间。多张表可以共用一个共享表空间,独立表空间则意味着每张表使用一个独立的表空间。
页内结构
数据页细分为七个部分:文件头(File Header)、页头(Page Header)、最大最小记录(Infimum+supremum)、用户记录(User Records)、空闲空间(Free Space)、页目录(Page Directory)和文件尾(File Tailer)。一般来说,这七个部分可以简化为 3 个部分:文件通用部分、记录部分、索引部分。
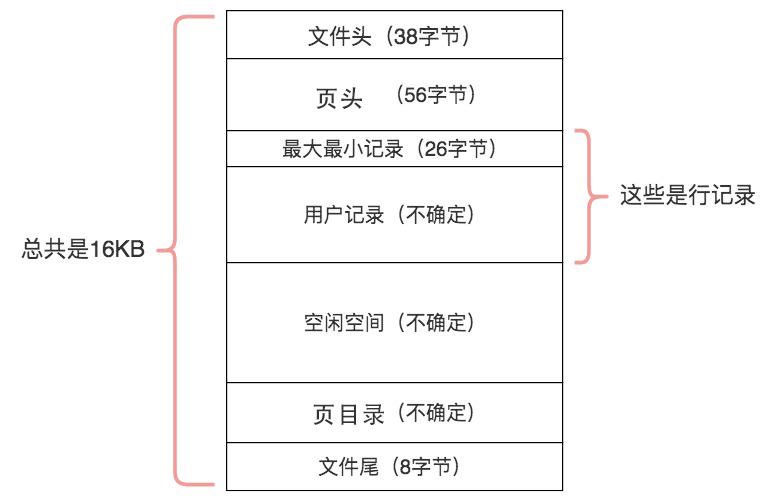
文件通用部分
文件通用部分包含文件头和文件尾,文件头中的两个字段充当指针分别指向上一个数据页和下一个数据页,相当于一个双向的链表;文件尾采用 Hash 算法校验页的传输是否完成。页头中存储数据页的各种状态信息,包括了第一条记录的地址,页目录中的槽数量,当前页在 B+树中的层级,索引 ID 等等。
链表的数据结构让数据页之间不需要是物理上的连续,而是逻辑上的连续。
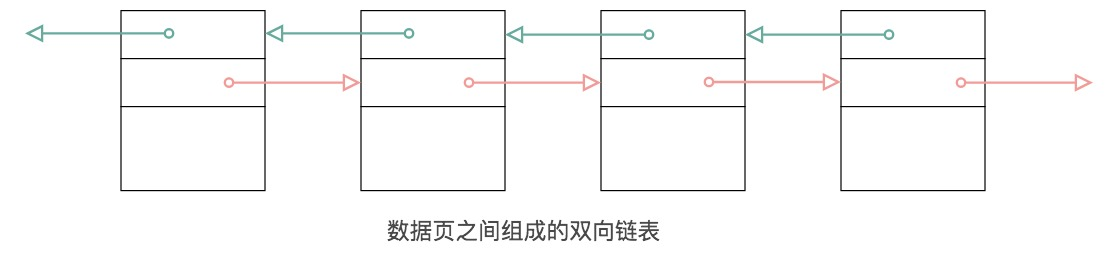
记录部分
记录部分主要有“最小最大记录”、“用户记录”和“空闲空间”。
索引部分
索引部分指的是页目录。由于记录的保存形式为单链表,为此页目录使用了二分查找来解决链表查找效率低的问题:将所有的记录分为几个组,分组 1 只包含最小记录。每个分组的最后一条记录的头信息中存储了该组的记录数量。页目录按照先后顺序存储了每组中最后一条记录的地址偏移量,地址偏移量又称为槽(slot)。因为槽的存储是有序的,所以可以使用二分查找检索记录。
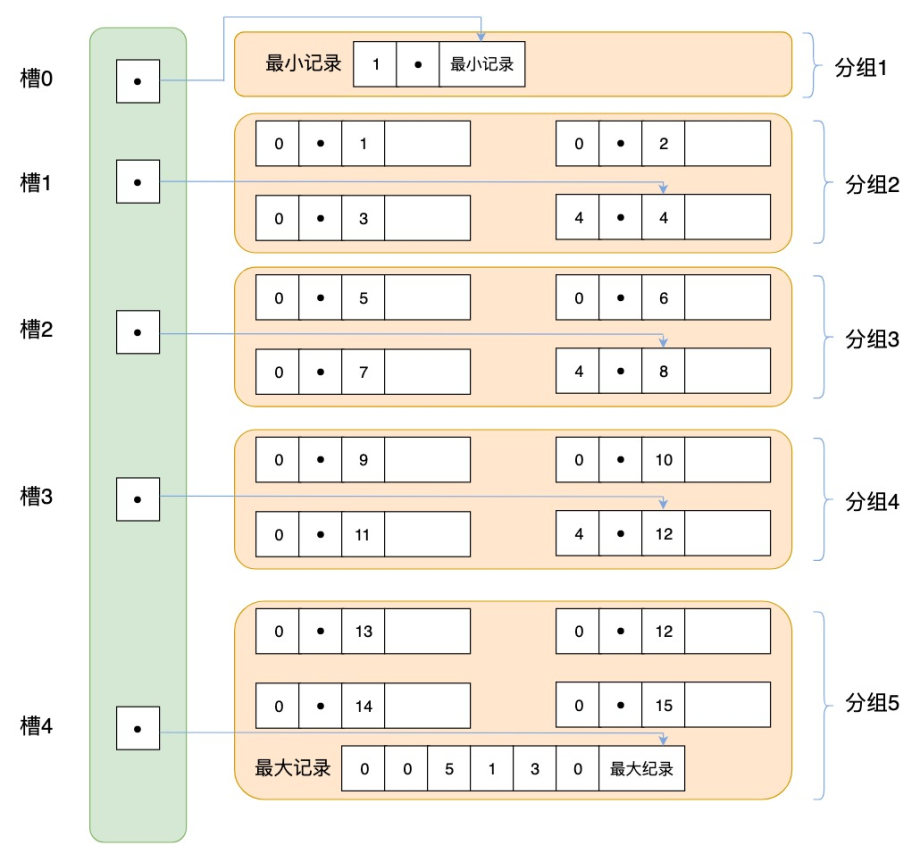
B+树索引
如果索引的构造方式为 B+树,那么查询记录首先从根结点开始,逐层检索,直到叶子节点。将该结点对应的数据页加载到内存中,页目录中的槽会通过二分查找定位到一个分组,然后在分组中通过链表遍历的方式查找到目标记录。
普通索引和唯一索引
读取一条记录时是将该记录所在的页加载到内存中,关键字是否唯一所消耗的时间可以忽略不计。所以采用普通索引还是唯一索引在检索效率上基本没有差别。
数据页加载
内存读取(较快)
如果数据在内存中,直接从内存读取。
随机读取(较慢)
在磁盘中对页进行查找,一个页面的读取时间往往较长。
顺序读取(效率高)
顺序读取是一种批量读取的方式,当请求的数据在磁盘上相邻存储时,顺序读取可以批量读取页面。采用批量读取的方式,即使从磁盘上读取数据,效率也比从内存中只读取一个页的效率高。