事务
事务是满足 ACID 特性的一组操作,它们要么全部执行(COMMIT),要么全部不执行(ROLLBACK)。
ACID 特性
四大特性中,一般认为原子性是基础,隔离性是手段,一致性是约束条件,而持久性是目的。
原子性(Atomicity)
原子性确保了事务不可分割,即事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚。
一致性(Consistency)
数据库总是从一个一致的状态转换到另外一个一致性状态。事务提交后或者事务发生回滚后,数据库的完整性约束不能被破坏。
隔离性(Isolation)
每个事务之间是相对独立的,不会受到其他事务的执行影响。事务结束之前对于其他的事务都是不可见的。
持久性(Durability)
一个事务提交之后对数据的修改是持久性的,即使在系统出现故障,修改的数据也不会丢失。
事务并发存在的异常
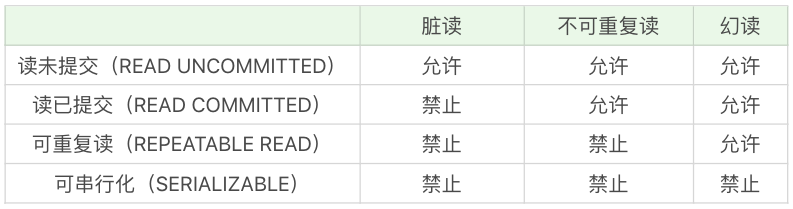
脏读
一个事务读取到了其他事物还没有提交的数据。
不可重复读
对某一条数据进行读取,发现两次读取的结果不相同,说明有其他事务对这个数据同时进行了修改或删除。不可重复的重点在于 UPDATE 或者 DELETE。
幻读
查询某一个范围内的数据行增多或者减小,幻读的重点在于 INSERT。例如事务 A 根据条件查询到了 N 条数据,但此时事务 B 更改或者增加了 M 条符合事务 A 查询条件的数据,导致事务 A 查询的会有 N+M 条数据。
理解
- 脏读强调事务读取到了无效的数据,因为该数据可能未提交或者回滚;
- 不可重复读强调的是同一事务两次读取的结果集内容不相同;
- 幻读强调的事务按照同样的查询条件两次查询出来的结果集数量不同。
隔离级别
在并发的环境下,SQL-92 标准定义了 4 中不同的隔离级别。
读未提交(READ UNCOMMITTED)
读未提交允许读取到未提交的数据,该情况下查询不会使用锁。
读已提交(READ COMMITTED)
RC 只能读取到已经提交的数据,该情况可以避免脏读的产生。
这种隔离级别也可以叫做不可重复读,因为两次相同查询,可能会得到不一样的结果。例如,T2 读取一个数据,T1 对该数据做了修改并提交,如果 T2 再次读取这个数据,那么读取的结果和第一次读取的结果不同。
可重复读(REPEATABLE READ)
RR 保证一个事务在相同的查询条件下查询的两次结果集内容相同。
RR 为 MySQL 的默认隔离级别。
可串行化(SERIALIZABLE)
可串行化强制将事务放在一个队列中按照顺序执行,是最高级别的隔离级别,同时牺牲了系统的并发性。
异常和隔离级别的对应关系
隔离级别越低,系统吞吐量和并发程度就越大,但同时意味着出现异常的增多。

数据表中的键
数据库中的键由一个或多个属性构成。
- 超键:能唯一识别元组的属性集叫做超键;
- 候选键:只含有一个属性的超键;
- 主键:候选键中的任意一个可以作为候选键;
- 外键:如果表 1 的某个属性集不为主键同时是表 2 的主键,那么该这个属性集就是外键;
- 主属性:包含在任一候选键中的属性;
- 非主属性:不包含在任一候选键中的属性;
函数依赖
部分函数依赖
设 X、Y 是关系 R 的两个属性集合,存在 X→Y,若 X’ 是 X 的真子集,存在 X’→Y,则称 Y 部分函数依赖于 X。
例:
(球员编号,比赛编号) → (姓名,年龄,比赛时间,比赛场地,得分);
(球员编号) → (姓名,年龄);
(比赛编号) → (比赛时间,比赛场地);
完全函数依赖
设 X、Y 是关系 R 的两个属性集合,X’ 是 X 的真子集,存在 X→Y,但对每一个 X’ 都有 X’ !→Y,则称 Y 完全函数依赖于 X。
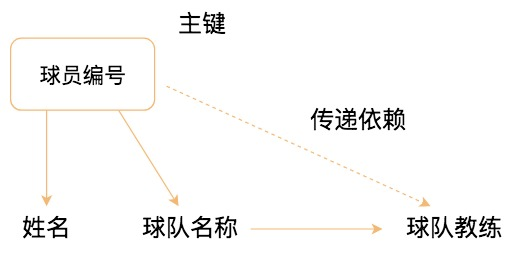
传递函数依赖
设 X、Y、Z 是关系 R 中互不相同的属性集合,存在 X→Y(Y !→X),Y→Z,则称 Z 传递函数依赖于 X。
范式
第一范式
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
第一范式(1NF)是指数据库表的每一列(任意属性)都符合原子性,都是不可分割的基本数据项。同一个列中不能有多个值,即数据表中的某个属性不能有多个值或者不能有重复的属性。简而言之,第一范式就是无重复的列。
第二范式
第二范式(2NF)要求数据表里的非主属性都要和候选键有完全依赖关系。
第三范式
第三范式(3NF)要求数据表满足第二范式的同时,对任何非主属性都不传递依赖于候选键。简而言之就是非主属性不依赖于其他非主属性。
反范式设计
越高阶的范式得到的数据表越多,数据冗余度越低。例如查询某个商品的前 1000 个评论,涉及到商品评论表和用户表。


1 | SELECT p.comment_text, p.comment_time, u.user_name FROM product_comment AS p |
上述查询代码的运行时间为 0.395,效率很低。因为显示评论需要显示用户的昵称,所以需要关联两张表进行查询。如果两张表数据量都超过了百万量级,查询效率就会变低。因为查询会在 product_comment 表和 user 表这两个表上进行聚集索引扫描,然后再嵌套循环。如果我们想要提升查询的效率,可以允许适当的数据冗余,在商品评论表中增加用户昵称字段。
1 | SELECT comment_text, comment_time, user_name FROM product_comment2 WHERE product_id = 10001 ORDER BY comment_id DESC LIMIT 1000; |
优化后之后只需要扫描一次聚集索引即可,运行的时间为 0.0395。
- 在数据量小的情况下,反范式会让数据库的设计变复杂。频繁采用存储过程来支持数据更新、删除等额外操作,容易 增加系统的维护成本。例如用户每次更改昵称的时候,都需要执行存储过程来更新,如果昵称更改频繁,会非常消耗系统资源。
- 当冗余信息有价值或者能大幅度提高查询效率的时候,我们就可以采取反范式的优化。反范式优化也常用在数据仓库的设计中,因为数据仓库通常存储历史数据,对增删改的实时性要求不强,对历史数据的分析需求强。这时适当允许数据的冗余度,更方便进行数据分析。
数据仓库和数据库在使用上的区别:
- 数据库设计的目的在于捕获数据,而数据库设计的目的在于分析数据;
- 数据库对数据的增删改实时性要求强,需要存储在线的用户数据,而数据仓库存储的一般是历史数据;
- 数据库设计需要尽量避免冗余,但为了提高查询效率也允许一定的冗余度,而数据仓库在设计上更偏向采用反范式设计;