Java 集合类主要由两个接口Collection和Map派生出来的,Collection主要为集合,Map主要为键值对。Java 集合类的主要框架如下,绿色标注的是常用的实现类。
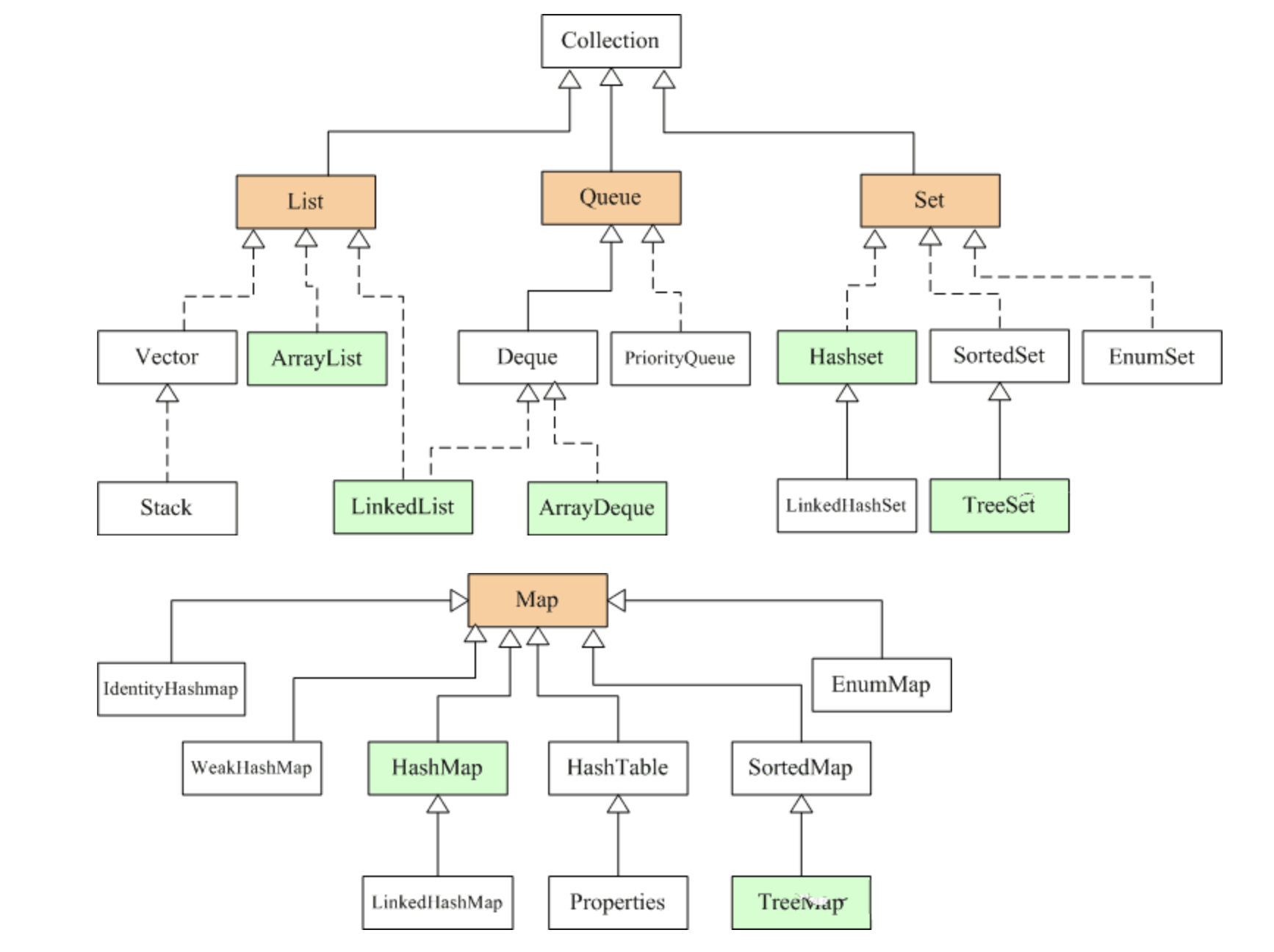
Collection
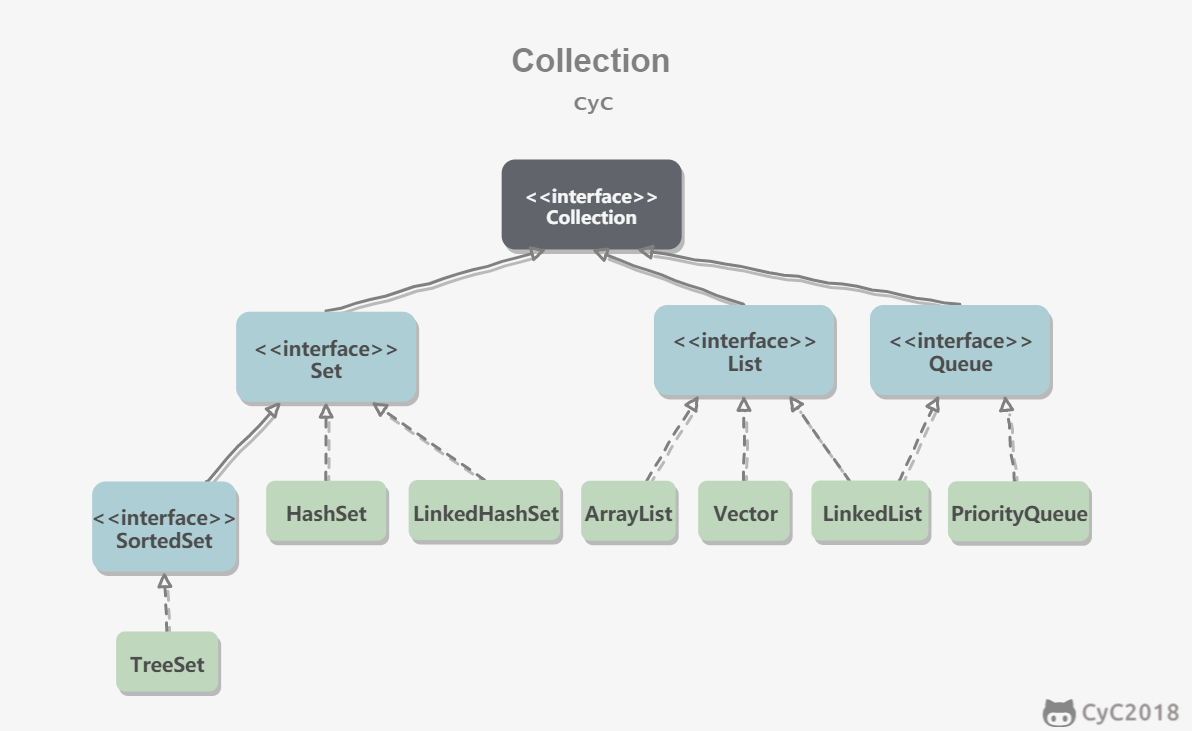
Collection派生出了Set、List和Queue三个接口。集合类中的元素需要重写equals() 方法和 hashCode() 方法。
Collection 的设计模式
迭代器模式
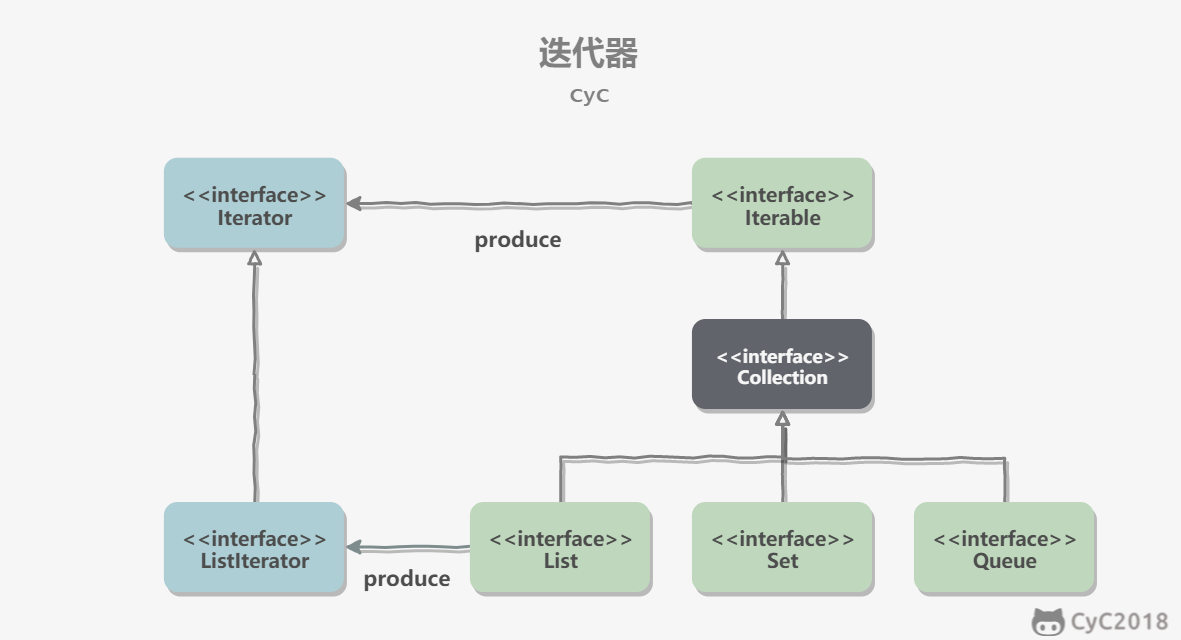
Collection继承了Iterable接口,其中的iterator()方法能够产生一个Iterator对象,通过这个对象就可以迭代遍历Collection中的元素。
从 JDK 1.5 之后可以使用foreach方法来遍历实现了Iterable接口的聚合对象。
1 | List<String> list = new ArrayList<>(); |
适配器模式
java.util.Arrays 的asList()方法可以把数组类型转换为List类型。
1 |
|
该方法的参数为泛型的变长参数,不能使用基本数据类型作为参数,所以只能使用对应的包装类。
1 | Integer[] arr = {1, 2, 3}; |
或者使用一下的方式:
1 | List list = Arrays.asList(1, 2, 3); |
Set
Set中的元素存放是无序的、不重复的。它只能通过元素本身来访问。实现类主要是:
HashSet:底层数据结构为哈希表。支持快速查找,查找效率为$O(1)$。但不支持有序性操作,也不包含元素的插入顺序信息。
TreeSet:底层数据结构为红黑树。支持有序性操作,但是查找效率低,为$O(logN)$。
LinkedHashSet:是
HashSet的子类,基于LinkedHashMap实现。具有HashSet的查找效率,内部使用双向链表维护元素的插入顺序。
HashSet、TreeSet 和 LinkedHashSet 的使用场景
HashSet 用于不需要保证元素插入和取出顺序的场景,LinkedHashSet 用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet 用于支持对元素自定义排序规则的场景。
List
List中元素的存放是有序的,并且可以重复。它可以直接通过元素的索引来访问,实现类主要为:
ArrayList:底层数据结构为
Object[]数组,支持随机访问。Vector:底层数据结构也是
Object[]数组,相比ArrayList是线程安全的。LinkedList:底层数据结构为双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)。只能顺序访问,不仅可以快速在链表中插入、删除元素,同时还可以用作栈、队列和双向队列。
ArrayList 和 Vector 的区别
Vector是线程安全的,ArrayList不是线程安全的。其中,Vector在关键性的方法前面都加了synchronized关键字,来保证线程的安全性。如果有多个线程会访问到集合,那最好是使用Vector,因为不需要我们自己再去考虑和编写线程安全的代码。ArrayList在底层数组不够用时在原来的基础上扩展 0.5 倍,Vector是扩展 1 倍,所以ArrayList更有利于节约内存空间。
ArrayList 和 LinkedList 的区别
- 底层数据结构:
ArrayList底层数据结构为数组,LinkedList底层数据结构为双向链表。 - 快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList实现了 RandomAccess 接口,所以有随机访问功能。 - 内存空间占用:
ArrayList需要为在列表结尾需要预留一定的空间。LinkedList中每一个元素的存储消耗都比ArrayList大。
- 插入、查找和删除元素的时间复杂度:
ArrayList插入和删除元素的时间复杂度受元素位置的影响,平均的时间复杂度为$O(n/2)$。索引越靠近表头越大,越靠近结尾时间复杂度越小。时间复杂度最大为$O(n)$,最小为$O(1)$。LinkedList在头尾插入、删除元素的时间复杂度为$O(1)$。插入和删除指定位置的元素的平均复杂度为$O(n/4)$,插入位置越靠近中间时间复杂度越大,最大为$O(n/2)$。
Queue
Queue是 Java5 之后新增的队列接口,其中的元素按特定的排队顺序来确定先后顺序,所以元素也是有序的、可重复。实现类主要为:
PriorityQueue:优先队列,底层数据结构是使用
Object[]数组实现的二叉堆。ArrayQueue:底层数据结构是
Object[]数组,通过双指针实现。
ArrayQueue 和 LinkedList 的区别
- 底层数据结构:
ArrayDeque是基于可变长的数组和双指针来实现,而LinkedList则通过链表来实现。 - 是否支持空数据:
ArrayDeque不支持存储NULL数据,但LinkedList支持。 - 扩容消耗:
ArrayDeque插入时可能存在扩容过程,不过均摊后的插入操作依然为$O(1)$。虽然LinkedList不需要扩容,但是每次插入数据时均需要申请新的堆空间,均摊性能相比更慢。
Map
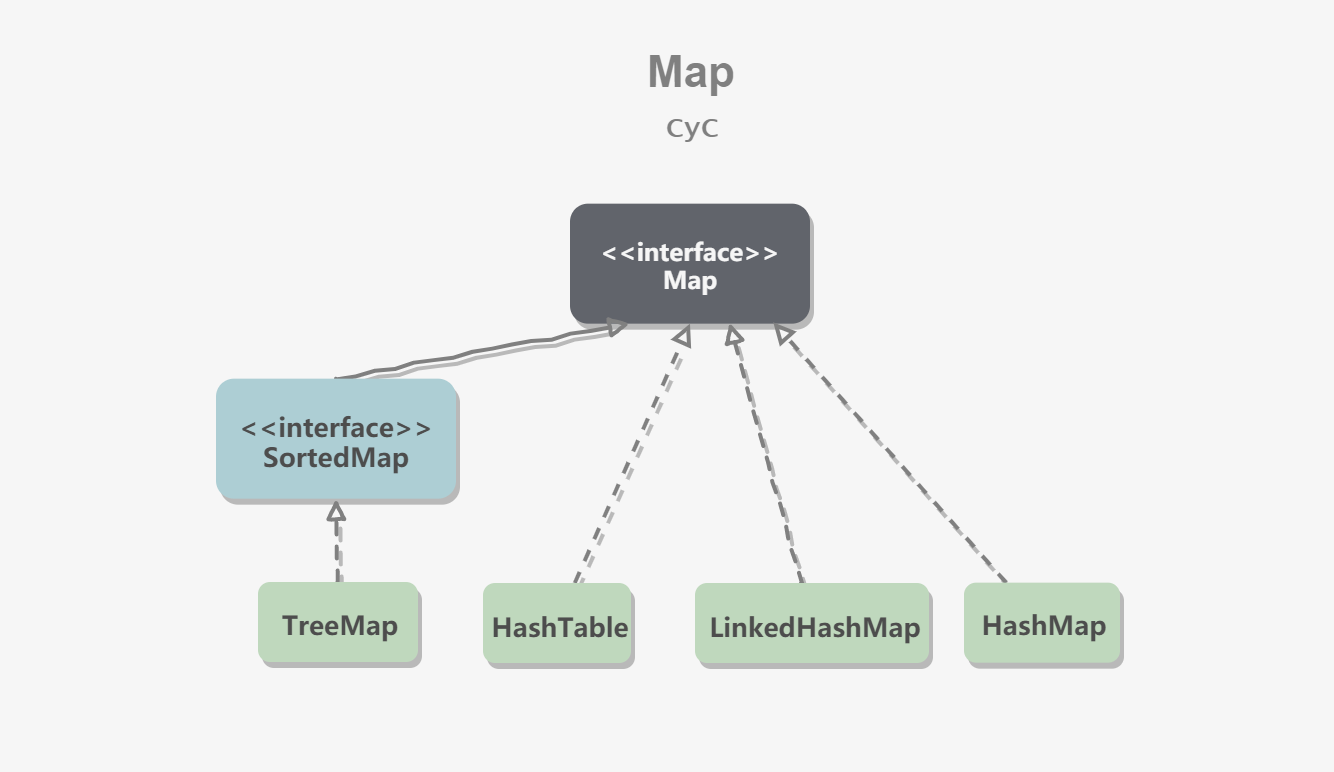
Map是一种存储 key-value 对的集合。其中,key 是无序且不可重复的,value 是无序但可重复的,并且相同的 key 最多映射一个 value。主要的实现类:
- HashMap:基于哈希表实现。
- TreeMap:基于红黑树实现。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
- Hashtable:和 HashMap 类似,但是是线程安全的。因为是遗留类,尽量不要使用。
HashMap 的底层数据结构
在 JDK1.7 中,底层数据结构为“数组+链表”,数组是 HashMap 的主体,链表主要是用来解决哈希冲突。JDK1.8 之后的版本将“链表”进一步修改为“链表+红黑树”。链表和红黑树会在到达一定的条件时自动转换:
链表的长度超过 8 且数组长度超过 64 时才会转换为红黑树;
数组的长度小于 64 时会先进行数组扩容,以减少搜索时间;
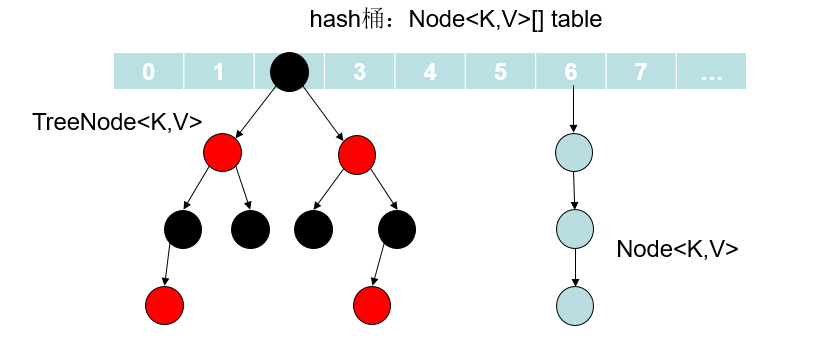
链表的搜索时间复杂度为$O(n)$,红黑树的搜索时间复杂度为$O(logn)$,所以当链表过长时会严重影响 HashMap 的效率,但是也不可以直接使用红黑树。红黑树的构造需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。如果一开始就用红黑树结构,元素太少,新增效率又比较慢,非常浪费性能。
HashMap 线程不安全的原因
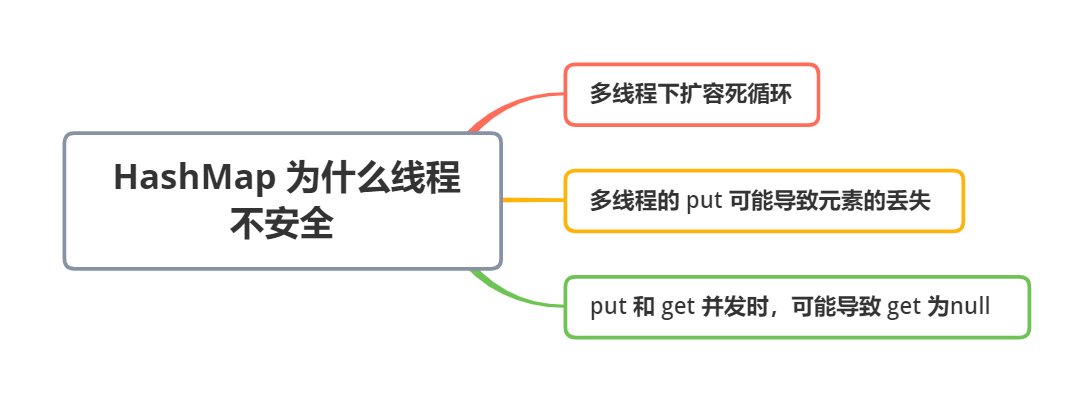
- 多线程下扩容会出现死循环。JDK1.7 中使用头插法插入元素,会导致环形链表。而在 JDK1.8 中使用尾插法,在扩容时可以保持链表元素原本的顺序,所以不会出现环形链表。
- 多个线程同时调用
put方法时,如果计算出来的索引位置相同,那就会导致前一个 key 被后一个 key 覆盖的情况,从而发生元素丢失。 put和get同时被调用时,可能导致get得到null的结果。例如线程 1 执行put时,因为元素个数超出 threshold 而导致 rehash,线程 2 此时执行get,就有可能发生这个问题。